Sunday, September 24, 2006
Land of the Free
Friday, September 22, 2006
CEOs are Vile
Much news and sports commentary focuses on the ever-larger paychecks of professional athletes. But even Peyton Manning is a day laborer compared to the modern Fortune 500 CEO. In May, Exxon Mobil shareholders passed the first resolution in company history to be enacted over opposition of the board of directors; at issue was shareholder fury regarding the $168 million retiring CEO Lee Raymond awarded himself in his final year. "There's some unhappiness about the way Raymond's compensation was handled," new Exxon Mobil CEO Rex Tillerson dryly told a news conference. During the summer Hank McKinnell was ousted as CEO of Pfizer. Over his last five years at the helm, he got $162 million, even as Pfizer earnings faltered. Carol Hymowitz of the Wall Street Journal reported that the head of Pfizer's "compensation committee" defended McKinnell's windfall on grounds of market forces in executive pay -- which in this context appears to mean, "CEOs at other companies are picking shareholders' pockets, too." There just wasn't anybody who would have taken the Pfizer job for less than $162 million? McKinnell's pay for his tenure atop Pfizer equates to $130,000 per work day.
African Pop
...and it wasn't. Why did the sound engineer insist on mixing them like some stupid rock band, with the thudding bass all the way up, obscuring the interlocking guitar figures?
Tuesday, September 05, 2006
xUnit for Scheme LISP
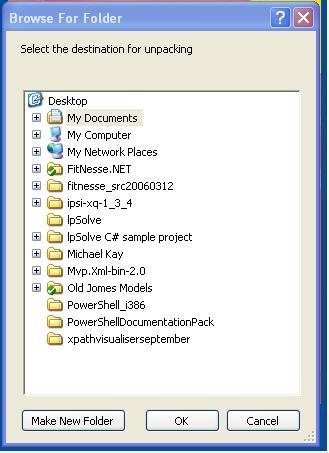
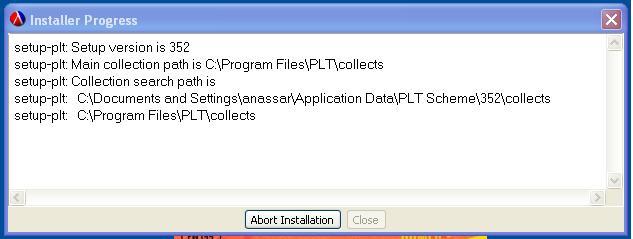
After a bit of pain, caused by my trying to install the SchemeUnit 2.0 download available on SourceForge, I managed to locate the 3.0 download here. I'm a novice when it comes to LISP, and to DrScheme, so the sparse installation instructions were inadequate for me. After some trial and error, which included messing up my DrScheme installation enough that I had to reinstall it, I found the happy path. First, I downloaded the .plt file and saved it an arbitary location (Firefox insists on showing the contents of the file as text, which is not what you want; I had to resort to IE).
Noel Welsh, the author of SchemeUnit, has dropped hints about how to install the .plt using planet, but my only goal is to learn a little more about LISP, and I don't want to be distracted by another utility. Noel's also turned out to be slightly inconsistent with the original documentation, as we'll see. In any case, Dr. Scheme's File menu has an Install .plt File... option, which seemed like the right method, so I clicked it and saw the dialog on the right. Which path to pick? After some trial and error, including a reinstallation of DrScheme, I noticed another dialog that had been concealed by the file selector. It turns out that I needed to navigate to C:\Program Files\PLT\collects, and make a new directory called schematics, after which I'd click OK and be happy forever. Oops! When I typed (require (lib "test.ss" "schemeunit")) at the DrScheme console, as SchemeUnit's Quick Start page says, it responded, "collection not found: "schemeunit" in any of [the paths displayed below]." D'oh! So, just to be one the safe side, I reinstalled DrScheme again, then followed the same steps as before to install the .plt file, but this time created a schemeunit directory within my PLT installation. It works! Now I actually have to write some LISP.
Saturday, August 26, 2006
Voodoo in New Orleans
Many of these are really quite different from those available here. Spanish and even Moorish song forms are still typical of son, for example, and there really is no Cuban equivalent of the 12-bar blues (though Guillermo Portabales's "Hay Jaleo" in in AAB form). There are also significant differences in the African material that predominates here and there respectively. Dizzy Gillespie, whose musical understanding of the rumba (the additional 'h' was some strange marketing trick) was beyond reproach, thought that the differences between jazz and rumba were due to drums having been "taken from" North American slaves. However, the slave trade to Cuba and that to North America didn't work the same way. The trade to Cuba continued longer; in Cuba, Africans could much more readily maintain their particular traditions (or, more accurately, they could build on them within Cuba, a comparatively large place; they could also integrate the musical forms brought by refugees from Haiti, or shipments of slaves from different areas). On the other hand, there's really no Cuban music that has "blue notes."
Paul Oliver noticed decades ago (cf. Savannah Syncopators) that blues sounds more like Malian than Ghanaian music, i.e., solo string instruments figure much more heavily than percussion ensembles. Gerhard Kubik built on this idea in such works as Africa and the Blues (American-Made Music). Slaves brought to this country may have lost some of their percussive knowledge, may have had less to begin with, or may simply have selected from among their musical options those most useful: those of savannah herders. Hence the "field holler," etc.
I have one quibble with Sublette's book, and that is that the rather nasty cultic practices of palo (conjury with dead body parts, etc.) are treated rather too enthusiastically. For me, only the music justifies the religion. As for New Orleans voodoo, I'm rather skeptical about how profoundly anyone has ever believed it.
Wednesday, August 23, 2006
Agility in Gov't Contracting
Matthew Patton, a programmer who worked on the contract for SAIC, said the company seemed to make no attempts to control costs. It kept 200 programmers on staff doing "make work," he said, when a couple of dozen would have been enough. The company's attitude was that "it's other people's money, so they'll burn it every which way they want to," he said.
Patton, a specialist in IT security, became nervous at one point that the project did not have sufficient safeguards. But he said his bosses had little interest. "Would the product actually work? Would it help agents do their jobs? I don't think anyone on the SAIC side cared about that," said Patton, who was removed from the project after three months when he posted his concerns online.
To respond preemptively to any defenses of SAIC, let me say that if they knew that they couldn't deliver, they should have refused to take any more money, money that came, in the end, from taxpayers. This isn't a game, people; we're talking about national security here.
Friday, August 11, 2006
Developers Considered as Obstacle to Agility
I must say that I like my job, and I like my coworkers. After working on government contracts for several years for employers and under project managers who could and did expressly forbid me the very use of testing and refactoring tools (Watir, Resharper, Eclipse, JMock, FitNesse, etc.), I ride the bus to Arlington in an enthusiastic mood. They are certainly the cleverest and most diligent team I've worked with in a good while.
Anyway, I'm not so much discouraged that my coworkers didn't rally to NUnit (some of them are familiar with JUnit; they seem to think it's just something you do in the Java world) and FitNesse after I brought the test coverage of a dismal yet significant code base up to 40% from 0% in a few months, as I am puzzled. I mused over this problem rather a lot during lulls in the action at Agile2006. At a status meeting at work last week, my jaw nearly dropped when the technical lead insisted that WinRunner was the appropriate tool for getting the application under test. I consider WinRunner to be a dead end, and in fact several teams near mine have attempted to make it part of their process and then given up. I don't want to review all the arguments against testing only through the GUI; I'll just say that if you test that way, you'll code that way, namely from the GUI on down, and your code will almost certainly be incoherent, just as if you code from the database schema on up. In one day, I managed to write tests in FitNesse that cover every single one of the use cases we were able to conceive for the application.
I should be pleased to have had the chance to create a fait accompli in FitNesse, yet it's somewhat tiring, always to have to carry out an alternative strategy before I can argue the case for it! My next goal is to configure CruiseControl.NET to pull the newest source from Subversion, rebuild it, run all the unit and acceptance tests, etc., and to make all this so easy that no one could think of doing things any other way. Until I've figured it out, everyone will continue to do manual testing. In fact, they'll continue even after I've created my next fait accompli.
Why? They're smart and diligent. Why do they not also realize how much time they waste every day? Perhaps the typical software developer's education provides him with an illusion that experience may never dispel, namely that if he simply throws himself at a problem the way he threw himself at assignments, he'll solve them. Then, of course, his professional progress becomes a matter of learning more about domains, or about platforms, but never about the resolute micrological analysis of one's own practices. Perhaps the most accomplished developer at my workplace, who participates in W3C's Binary XML Working Group, considers TDD to be unsuitable for "deep programming." It's not worth my time to debate him, here or to his face. The point I want to make is that the agile community's characterization of the resistance to agility as coming from "pointy-headed bosses" (yes, I heard this phrase more than once Agile2006), or from within "dysfunctional" organization, or from customers (!), is wrong. Competent developers are the source of this resistance, developers whose history of accomplishment deceives them that they don't need to think any harder about how they do things. Kent Beck, in Extreme Programming Explained, 2nd ed., has argued that overwork is, paradoxically, a retreat from professional responsibility. Yet overwork is strangely tempting to developers—I'm still tempted even now, when I have two small boys at home—so I can only conclude that on some level, we think that what our job is about is cranking out code, rather than exercising good judgment.
As evidence, I would present the odd attachment that my technical lead has to WinRunner, and to test plans written in Excel! As a software developer, in Northern VA and Silicon Valley, I have had 8 different technical leads, all of them entirely competent developers, and every single one, when he became a manager, suddenly developed a mania for Gantt charts, or documentation that immediately and obviously got out of sync with the application's functionality, Microsoft Word documents specifying variable naming conventions or coding standards, or, quel horreur, IEEE 830 requirements! Every one, in other words, was utterly incapable of analyzing his own and his subordinates' productivity, believing instead that imposing additional such adventitious requirements on the only sort of development they'd every practiced could be possible, desirable, and effective. In my experience, when my development process actually conformed to a prior Gantt chart, that was due to dumb luck, deliberate ass-dragging, or retrofitting the Gantt chart entries to the work I'd actually done with my manager's explicit approval. Is this poignant, or hilarious?
In short, the resistance to agility, to the continuous and deliberate analysis and refinement of one's modus operandi individually and as part of a team, conflicts with a profound motivation of many software developers: to do as much of it as they can without thinking about how they do it. The avoidance of self-reflection, let alone the kind of reflection that pair programming induces, becomes a professional prerogative. I think of TDD as a kind of carefully calibrated negative reinforcement, in which one purposefully causes only as many tests to fail as one can easily fix. In return, of course, one gets the positive reinforcement of the green bar. In contradiction to the frequent claim that TDD should be the most attractive practice to introduce first to a team, many developers resist precisely this practice, because it seems like the intrusion into their personal space of a less intelligent alter ego, one who purposefully writes code that he knows won't work! Even younger developers will say, "I know how to do this; why would I test it first?" If you begin with that attitude, it can take an extreme effort of will to let go of it when you really do know how to do things.
Monday, August 07, 2006
The Change-Counting Algorithm & TDD
At any rate, SICP poses this problem in Chapter 1: "How many different ways can we make change of $ 1.00, given half-dollars, quarters, dimes, nickels, and pennies? More generally, can we write a procedure to compute the number of ways to
change any given amount of money?" There is, it turns out, a fair amount of literature on this problem (cf. David Pearson's paper, or
What This Country Needs is an 18 Cent Piece). Despite having the solution right in front of me, an implementation eluded me until I really considered the structure of the problem, which is recursive. The authors provide unequivocal hints: "Consider this reduction rule carefully, and convince yourself that we can use it to describe an algorithm if we specify the following degenerate cases: 1, If a is exactly 0, we should count that as 1 way to make change; 2, If a is less than 0, we should count that as 0 ways to make change; 3, If n [the number of available denominations] is 0, we should count that as 0 ways to make change." These should be the starting points for the test-driven development of the algorithm, but I only understood their significance within the recursion after pondering the problem while riding the bus. Imagine you've got quarters and pennies, and are asked to make $.26 in change. You can try to use 1 quarter. Now you've got to make $.01 with quarters and pennies. If you use another quarter, you've then got to make - $.24, at which point condition 1 will obtain; if you use a penny, you'll then have to make $.00, at which point condition 2 will obtain (and the recursion will stop). Condition 3 will also stop the recursion, i.e., you've got no more denominations to try. Once I'd understood all this, I could eliminate some of the recursive calls by using integer division, i.e., the largest number of quarters that I can use to make a will be a / 25.
After that, I quickly wrote the following code in Python, and indeed this implementation evolved in order with precisely these tests:
import unittest
def countChange(amount, coins):
if amount == 0:
return 1
if len(coins) == 0:
return 0
if len(coins) == 1 and amount % coins[0] == 0:
return 1
currentCoin = coins[0]
remainingCoins = coins[1:]
currentPossibilities = [currentCoin * i for i in range(0, amount / currentCoin + 1)]
return sum([countChange(amount - p, remainingCoins) for p in currentPossibilities])
class TestCountChange(unittest.TestCase):
def testAmountZeroWithNoCoins(self):
self.assertEqual(1, countChange(0, []))
def testAnyAmountWithNoCoins(self):
self.assertEqual(0, countChange(100, []))
def testAmountZeroWithAnyCoins(self):
self.assertEqual(1, countChange(0, (1, 5, 10)))
def testAmountsWithOneCoin(self):
self.assertEqual(1, countChange(1, [1]))
self.assertEqual(1, countChange(5, [5]))
self.assertEqual(1, countChange(10, [10]))
def testAnyAmountWithPennies(self):
self.assertEqual(1, countChange(10, [1]))
self.assertEqual(1, countChange(10000, [1]))
def testMultiplesOfSingleCoin(self):
self.assertEqual(1, countChange(100, [5]))
self.assertEqual(1, countChange(100, [50]))
def testTwoKindsOfCoins(self):
self.assertEqual(2, countChange(10, [5, 10]))
self.assertEqual(2, countChange(7, [5, 1]))
self.assertEqual(0, countChange(7, [5, 10]))
def testTextbookExample(self):
self.assertEqual(292, countChange(100, [1, 5, 10, 25, 50]))
if __name__ == '__main__':
unittest.main()
Wednesday, August 02, 2006
Generating A Regular Expression
ATGGCACAGGTTATCCATTATCAGACCTTTACAAAAATCAGATAA, allowing exactly 1 mismatched character? Trust me, the patterns get a lot longer than this! Anyway, inexact matching algorithms would be too inefficient here: we know exactly how many mismatches we're allowed. On the other hand, I'm not sure that any solution could take advantage of optimized exact matching algorithms, whether those were part of a regex implementation or a custom implementation. At first, I considered how to write an expression that allowed a single mismatch somewhere in the pattern; then I realized that the general case, allowing m mismatches, is actually easier to write. I would like to present this work as part of a prospective talk on "test-driven development and recursive algorithms," or something like that, but to be honest, this provisional implementation was preceded by a lot of trial and error. At some point, however, I knew how the algorithm had to work, and how the expression had to look, and at that point, of course, it was easy to employ TDD.OK, here it is, in Python:
import unittest
def expand(s, mismatches):
assert mismatches <= len(s)
# Only exact matching from this point on.
if mismatches == 0:
return s
# All mismatches allowed.
if mismatches == len(s):
return '.' * mismatches
# Branch: match the next character exactly, or mismatch.
return [[s[0], expand(s[1:], mismatches)],
['.', expand(s[1:], mismatches - 1)]]
def collapse(l):
if type(l) == str:
return l
if type(l[0]) == str:
# They're all strings, in this case.
return ''.join(map(collapse, l))
return '(' + '|'.join(map(collapse, l)) + ')'
class TestExpansion(unittest.TestCase):
def testZeroMismatches(self):
self.assertEquals('string', expand('string', 0))
def testOneCharOneMismatch(self):
self.assertEqual('.', expand('a', 1))
def testMultipleCharsAllMismatches(self):
self.assertEqual('..', expand('ab', 2))
def testTwoCharsOneMismatch(self):
self.assertEqual([['a', '.'], ['.', 'b']], expand('ab', 1))
def testCollapseString(self):
self.assertEqual('a', collapse('a'))
def testCollapseTwoStrings(self):
self.assertEqual('(a.|.b)', collapse([['a', '.'], ['.', 'b']]))
def testThreeCharsOneMismatch(self):
l = expand('abc', 1)
self.assertEqual( [['a', [['b', '.'], ['.', 'c']]], ['.', 'bc']], l)
r = collapse(l)
self.assertEqual('(a(b.|.c)|.bc)', r)
if __name__ == '__main__':
unittest.main()
And it seems to work, according to my understanding of what it should be able to do! I'd like to turn on "explicit capture only", to spare the expense caused by all those parentheses, but Python doesn't have that option:
>>> r.findall('tony bony tiny toby tonk toaa blah')
[('tony', 'ony', 'ny'),
('bony', '', ''),
('tiny', 'iny', ''),
('toby', 'oby', 'by'),
('tonk', 'onk', 'nk')]
>>>
Tuesday, July 18, 2006
Generating Column Fixtures for Collections Known at Runtime
!|Validation.BaseFileListingFixture|C:\FitNesse\dotnet|*.*|
|file name|do stuff?|
|*|0|
...and in this case the DoStuff() method would simply compare the file size to 0. Something like that.
The code works out differently in Java and C# (the former was easier; the latter required me to hack into Fit more than I would have liked). I can send you either one if you drop me a line. I had to eliminate the code from this posting because it ruined the format of the blog; can't have that!
Tuesday, July 04, 2006

Monday, July 03, 2006
Welcome, Leo!
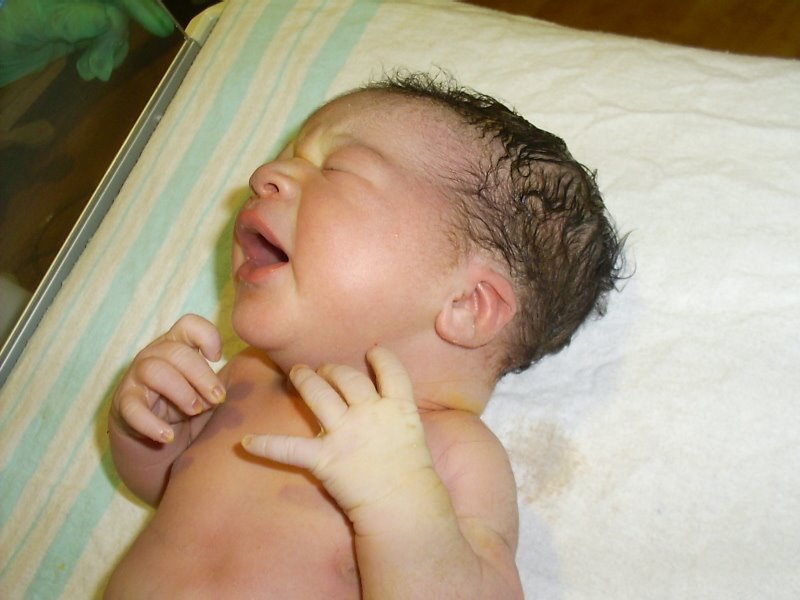
I have now been blessed with two lovely little boys: Carlo, age 4, and Leo, just a few days old!
Monday, June 26, 2006
Generating C# from XML: A Mixed Blessing
[XmlSerializable]
public class LegacyClass {
[NonSerialized]
public Type ValueType { ... }
public TypeEnum ValueTypeEnum {
get { based on ValueType property }
set { likewise }
}
}
Similarly, events have to be marked thus:
[field:NonSerialized]
public event BlahHandler Blah;
The field qualifier causes the compiler to apply the attribute to the underlying multicast delegate field. An event is not serializable as such.
Still, after only half a day, I realized that my effort to leverage .NET's handy code generation for XML serialization of a class was adding more cruft to an already crufty code base, that any unit tests I tried to create as motivation for my new code were compromised by the low quality of the code I was adding to, that I would have to version these additions without knowing what effect they would have on the application as a whole...that I was driving blind, in other words. Our XML wizard advised me simply to write all my custom serialization code (via the ISerializable interface)...and at that point, I knew I was getting into pissing-match territory. I simply don't feel any need to prove myself by writing this code. I'm perfectly happy accepting the output from the VS2003 xsd.exe utility. The only obstacle was that I didn't have an XML schema to work from! All I had was the existing and very unorthodox custom serialization code that was already in place, which navigated a DOM, thus losing the performance advantages of custom serialization.
So I decided to use the memento pattern: treat XML as a persistence layer, generate a .cs file from a schema that I would have to create incrementally, based on what I could learn about the object graph and interpose a factory class that could populate the memento from the object graph or vice versa. Now all my serialization code is in one place, and testable as such, and I need never break the existing code. All I have to do is deserialize the XML, serialize, create a DOM, and determine what was lost during the round trip. Then I extend the XML schema, regenerate the .cs file for the memento, and repeat as necessary. I sidestep the existing deserialization code, and continue extending my factory until it creates an object graph that works, or seems to work. This latter step is obviously the difficult one, since I don't really know what the application requires in order to work properly! Ultimately, my factory has to reverse-engineer the existing code, but I can avoid destabilizing that code by virtue of having a completely discrete factory class in a separate file, and write unit tests in a strict A/B fashion (i.e., compare the object graph produced by my factory with that produced by the legacy code).
Then I dump the legacy code and open the champagne!
Tuesday, June 20, 2006
Running Fit via Visual Studio
Nonetheless, I've felt the need this week to single-step through some legacy code that is exercized by tests I wrote in FitNesse. I willingly concede that this feeling is evidence of some kind of failure, perhaps my own and not just the legacy coders'. The appropriate FitNesse documentation was not entirely clear to me, perhaps because I needed to better understand how FitNesse works in the first place. It seems obvious now that the test runner would have to get the HTML representing the tests from FitNesse, but I didn't quite grasp that. However, the application that needed to call my code is C:\FitNesse\dotnet\TestRunner.exe. In order to have TestRunner invoke my code (single-stepping through your own fixtures, let alone TestRunner or the Fit code, takes a little more work), I needed to open the Property Pages for the project and change the Debug Mode setting from "Project" to "Program," after which I could specify the Start Application. I then set the Command Line Arguments to -debug -nopaths -v localhost 8080 SerializationSuite.RoundTripSuite Validation.dll, though not all of that is required. My FitNesse server is listening on port 8080, so yes, those options are required. -debug and -v lead to more console output, though they might provide you with more insight into what, precisely, TestRunner is doing. FitNesse has to provide the tests, and in this case the tests that drive the problematic code are on the specified page (i.e., I normally see them at http://localhost:8080/SerializationSuite...). Validation.dll is the project output; in this case it contains custom fixtures. The Validation project references the code I want to bring under test; those DLLs are copied to the Validation project by default. If I set the Working Directory to the bin\Debug directory for the project, TestRunner should be able to find all the necessary DLLs. fit.dll and fitLibrary.dll should have been installed to the same directory as TestRunner.exe. I specified -nopaths in order to avoid any potential collisions with paths set in FitNesse. At this point, TestRunner can find all the DLLs it needs, so I can freely hit F5, just like in the old days, when I was looking for dangling pointers in C++.
